
Search Resources: Advanced
Dataset Transformations
Sometimes your source data is not ideal for consumption by an AI Agent. Transformations enable you to use an LLM and Functions to transform data prior to indexing it. Transformations have many use cases:
| Use Case | Description |
|---|---|
| Rewriting | Use an LLM to rewrite your source material
|
| Scrubbing | Use an LLM to remove markup from your source content
|
| Augmenting | Use an LLM to add new information to your source material
|
| Structuring | Use an LLM to induce more structure to your source material
|
| Classifying | Use an LLM to classify records and potentially filter them
|
| Splitting | Use an LLM (or pure python) to split up material
|
At a high level, you build transformations to either filter, split or improve your dataset records, or to create ideal string properties for index embeddings . Transforming data can improve agent behavior while reducing the need for live prompt chaining and thereby reduce agent latency.
Transformation Engines
Transformation Engines are where you build out transformations. They have some similarities to agents:
- They are versioned
- They can chain LLM calls
- They use Functions
They are different in that they perform a batch execution on each record in a Dataset and thereby produce a new dataset.
A single engine can expose multiple transformations. In the following screenshot, the user has opened an engine called Book Transformations that defines two transformations:
- Filter old topics - goal is to filter out books about outdated technology
- Twitter -> X - goal is to rewrite any book descriptions that mention Twitter to say 'X (formerly Twitter)
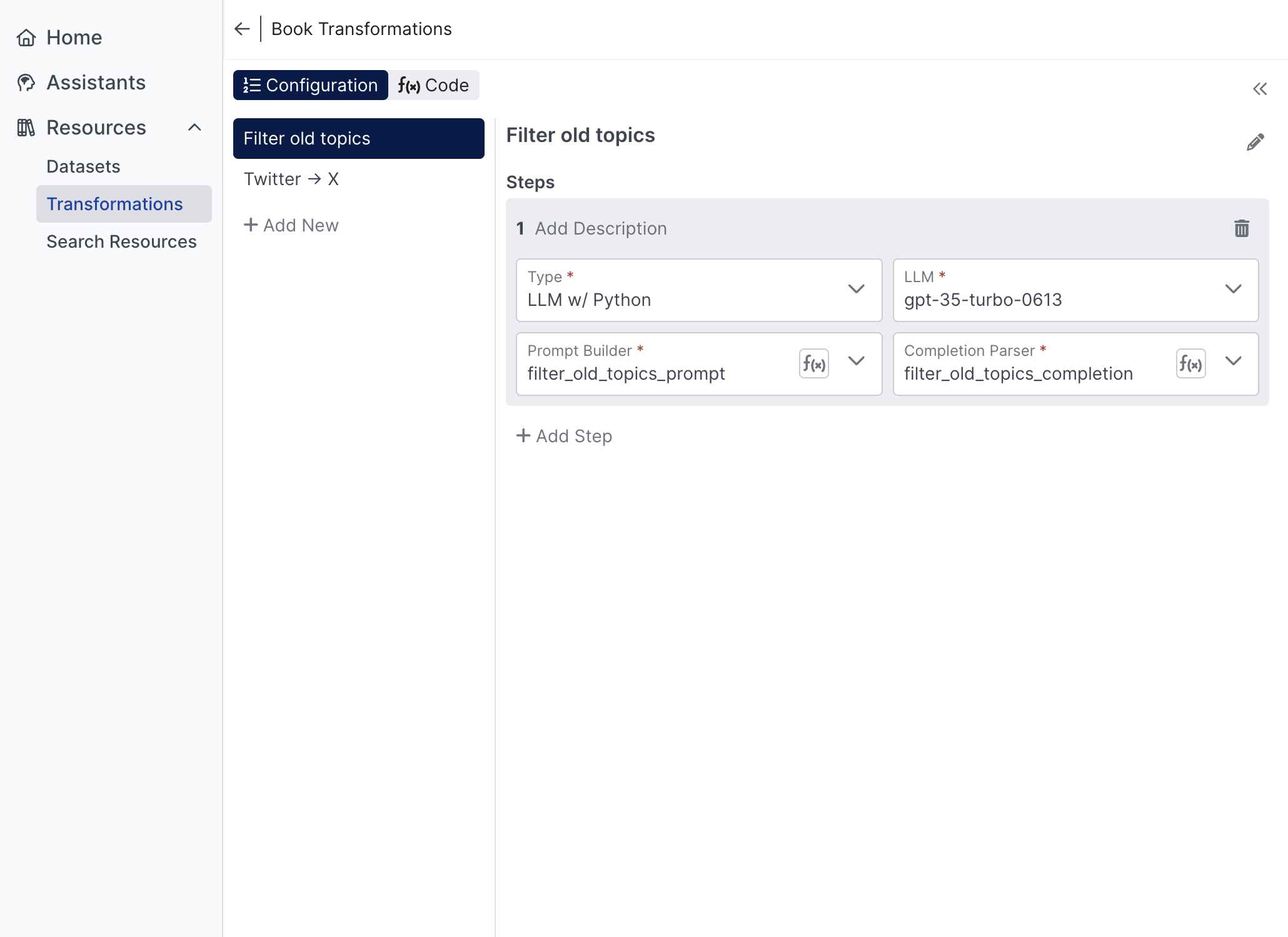
Transformations within the same engine are versioned together, share the same code base, and can be composed of one another.
Transformation Steps
Individual transformations are defined by steps. Transformation steps take one record at a time as input, and output 0 to many transformed records. There are three types of steps:
- Prompt AI - given a record, construct a prompt. Use the completion to modify, filter or split the record
- Call Function - given a record, use pure python to potentially modify, filter or split the record
- Call Transformation - run another transformation within the same engine
Prompt AI Step
The most powerful transformation step type is the Prompt AI Step. It is similar to the Prompt AI Behavior , but instead of operating on a context it operates on one record of a dataset at a time. It requires both prompt builder and completion handler functions. Rather than returning actions like the Prompt AI Behavior, the completion handler returns a list of records. This leads to three possibilities:
- If the list is empty, the input record is filtered out during the transformation
- If the list has one element, it's considered to be the transformed version of the input record (for that step)
- If the list has multiple elements, then one input record became multiple output records
Dataset records are always JSON objects. Accordingly, python transformation steps are expected to output records as dictionaries.
The following code snippet demonstrates using the LLM to perform a classification that is then used to filter records out of the dataset.
def filter_old_topics_prompt(record, llm):
prompt = f"""
I'm going to present you with the title and a short description of a technical book.
Your your job is to determine if the book is about any of the following outdated subjects:
Silverlight, ASP.net
Book title: {record['title']}
Book description: {record['shortDescription']}
Return "true" if the book is about one of the outdated topics, otherwise return "false"
"""
nested = [{'role': 'user', 'content': prompt}]
return {'prompt': nested}
def filter_old_topics_completion(record, completion, prompt, llm):
if 'true' in completion.lower():
return []
else:
return [record]Call Function
A python step uses a single Function to transform one input record into zero to many output records. It's handy if you want to do things like filter on data already present in the dataset, or derive a property by concatenating two other properties.
def combine_descriptions(record):
record['combinedDescription'] = record['shortDescription'] + "\n\n" + record['longDescription']
return [record]Call Transformation Step
The run transformation step allows you to call another transformation defined in the same engine. This allows for transformations to be composed of smaller transformations which can be handy for both reuse and testing. In the case of the Book Transformations engine, we could add a third transformation to the engine that both filters out books about outdated topics and renames Twitter by calling the other two transformations.
Debugging Transformation
Building transformations out of prompts and Functions requires a tight development loop just like in the Agent Designer. You can quickly test a transformation from the right panel of an engine. Just select the dataset and transformation you want to test and hit the Test button. The transformation will then be run on a small subset of the dataset in dry-fire fashion (no results are saved):
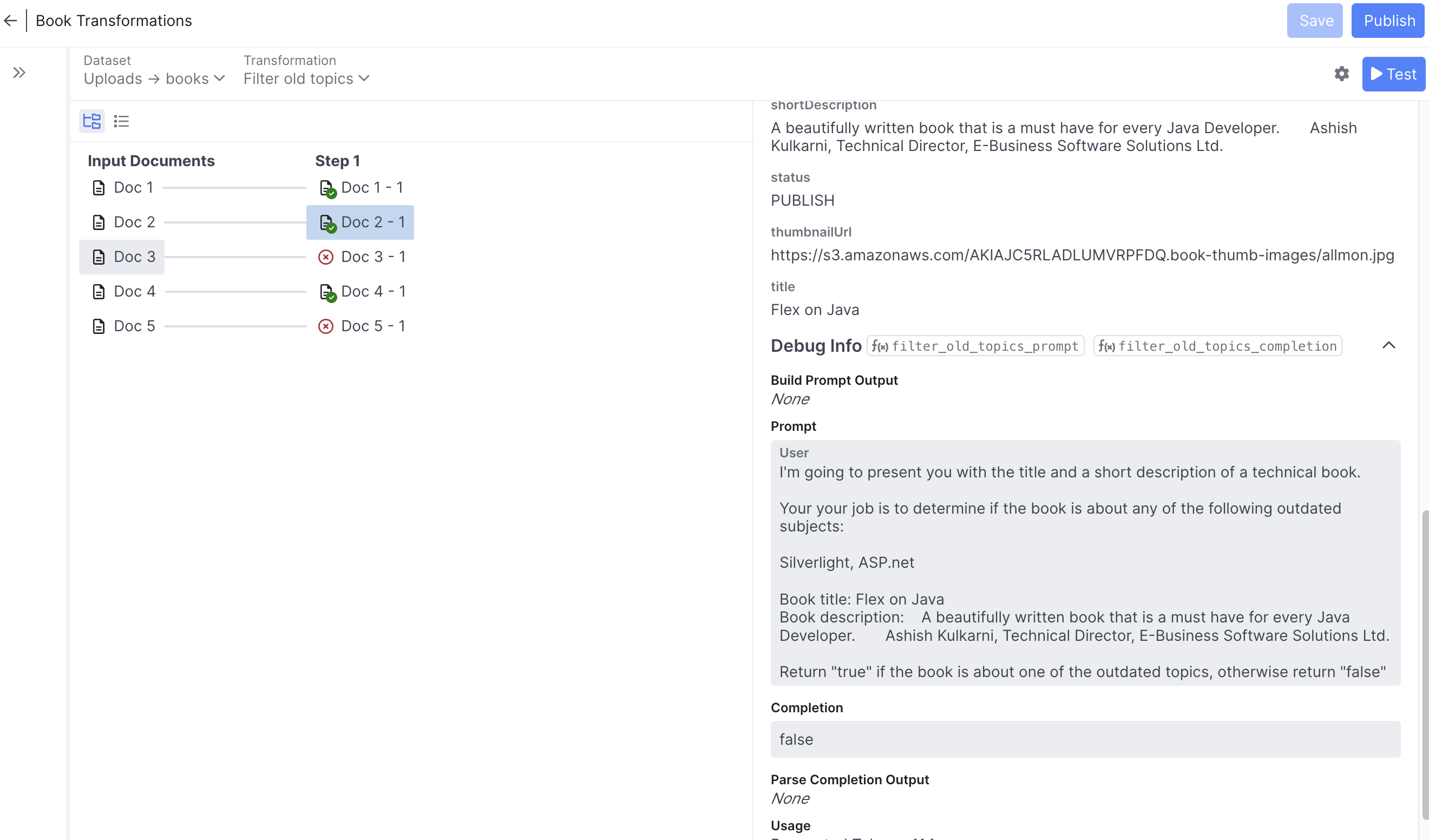
On the left you can see a trace of how the test records were transformed at each step. Selecting a record will show you its state after that step (or the error that occurred if any). On the right, you can see all of the record properties with annotations about which properties were added or removed in that step, as well as trace information specific to the step-type. For prompt steps, you can see the prompt, completion, token usage & more.
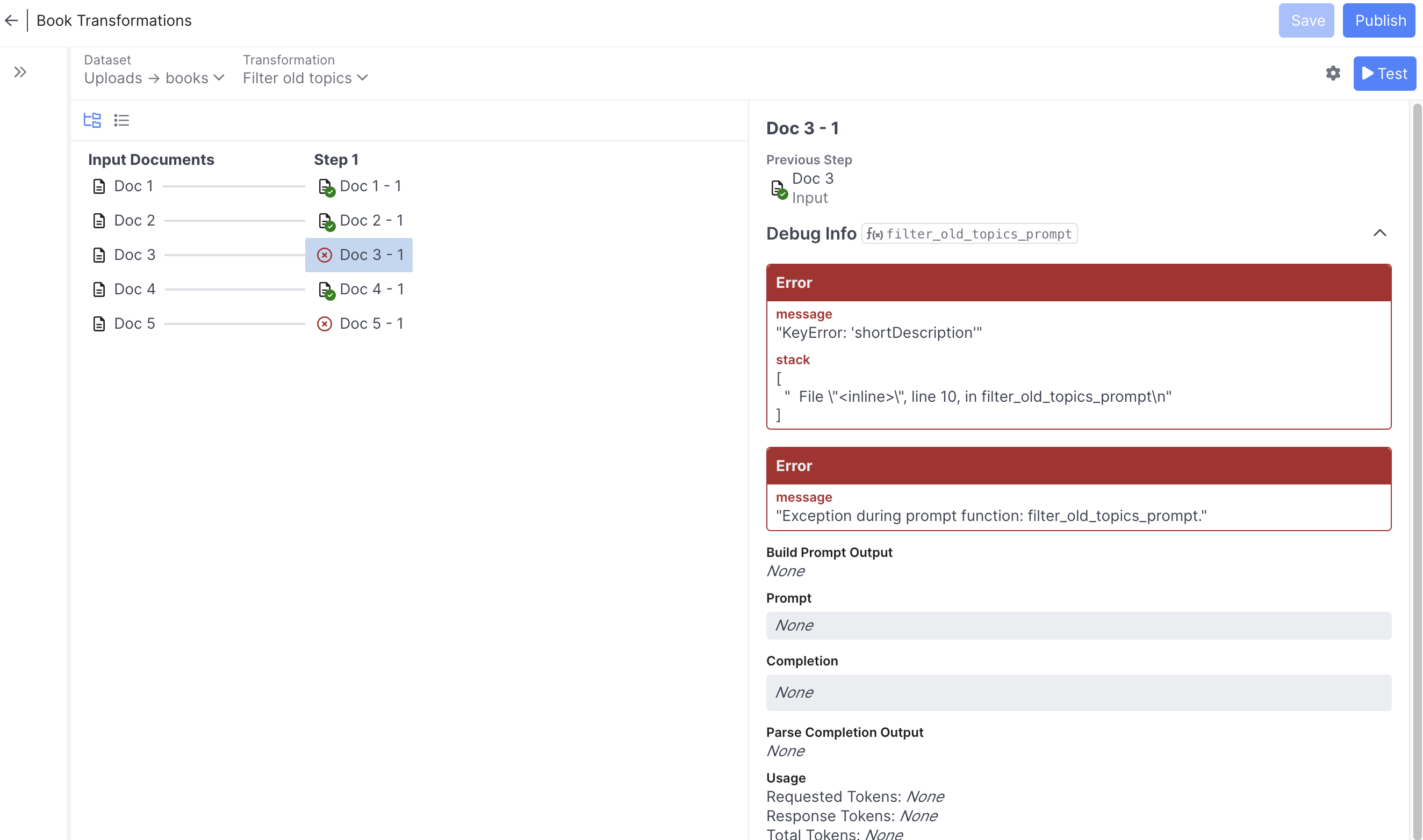
Here we can see the cause of the error on the third test record (apparently not all books have the shortDescription property)
The transformation test button is invaluable for getting your code and prompts working quickly. Note that by clicking the gear icon by the test button, you can adjust the number of test records as well as the starting record row so that you can control which records you're testing.
Running Transformations
Once your transformation works well in test mode, it's time to execute it for real on a dataset. Ensure that you've saved and published your transformation engine. Then, head back to Datasets and find the dataset you wish to transform and select 'Run Transformation' from the Actions menu in the upper right. You will then be prompted to choose a transformation to run and whether you want to overwrite an existing dataset or create a new one.
Note: You cannot overwrite datasets with indexes that are linked to search resources. The only way to modify a dataset that is linked is via Synchronization .
Transformation execution can take hours depending on the number of records and number of LLM calls. You can monitor progress from the Datasets area. You can also monitor the Event Log for any errors that may occur, and can cancel the transformation if necessary. Transformation LLM calls are cached so if the majority of prompts don't change, things will speed up significantly on a subsequent transformation or sync.
When the transformation is complete you can do several things:
- Index and link the new dataset to a search resource to explore the full results of your transformation
- Download the transformed dataset for inspection outside of AI Studio
- Hook up the transformation to run as part of dataset Synchronization
Dataset Synchronization
Datasets originate from external systems. In early development you’ll likely work with a static (and possibly reduced) copy of your source data as you develop transformations and evaluate your search resource. As you get closer to deployment you may wish to establish recurring dataset updates. That’s where the Dataset sync API comes in.
To enable synchronization, go to the Synchronization tab and enable the toggle. At this point you need to copy the dataset ID for purposes of calling the API. This can be found by clicking the information icon to the right of the dataset name. When a dataset is synced, the following steps occur:
- The latest data is downloaded
- If a transformation is set on the Synchronization tab, the new data is transformed accordingly
- The data is re-indexed according to the indexes defined prior to the sync
- If the new data passes the Publish Condition then all linked Search Resources are updated in-place
- Any errors that occur and the final status of the sync are logged to the Event Log
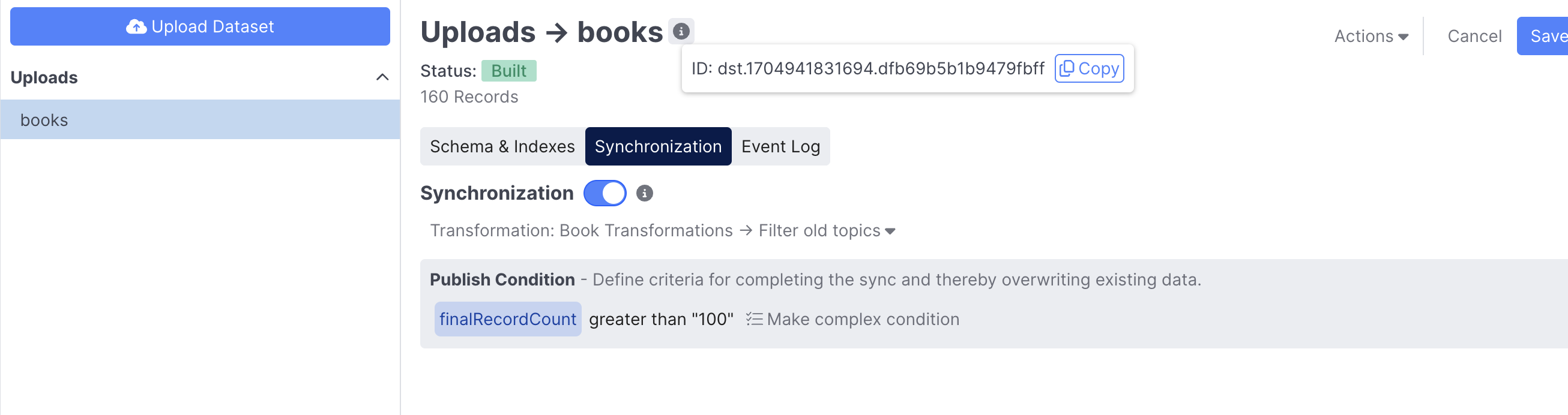
If your source data requires transformation prior to being indexed, select the appropriate transformation from the dropdown. Transformation results are cached so subsequent syncs will go much faster if the transformation engine hasn't changed and most of the dataset records are the same.
You can also configure a Publish Condition. Generative agents are largely a product of the search resources they consume. In that sense, syncing a dataset directly impacts the behavior of what is potentially a production agent. Typically this is a good thing so that your agent stays up-to-date. But, it can be bad if something goes wrong in the sync. The publish condition allows you to assert that conditions like number of records is greater than X and the number of errors is less than Y are true. This prevents a healthy search resource from getting overwritten with a broken one.
Invoking the API
In order to invoke the API, you’ll need access to a Quiq API Key. You also need your source data in one of the supported dataset formats. You then have a choice in how you invoke the API:
- Make the source data available through a publicly visible URL. S3/Blob store presigned URLs are a great way to make the data temporarily available to Quiq without making it discoverable. Pass the url in the
syncUrlprop. - Use the Prepare Upload API to upload the dataset to Quiq’s servers for further processing. Pass the uploadId in the
syncUploadIdprop
Option 2 is limited to file sizes less than 25MB.
Here’s an example Python script that demonstrates option 2: https://github.com/Quiq/api-examples/blob/master/ai-resources/sync_dataset.py
Set QUIQ_API_KEY_IDENTITY and QUIQ_API_KEY_SECRET in your environment, and then execute it like this:
./sync_dataset.py --host https\://<tenant>.goquiq.com --dataset-id <datasetId> <path to source data file>
A 200 response from the server indicates that your request to sync has been received. The request will be fulfilled asynchronously.
Practical Tips
- When working with a large dataset and developing transformations, consider uploading a smaller subset as well. You may want to use it to test your transformation on more records before committing to run on the entire dataset
- Don't feel like embedding properties have to contain a single piece of information. The best embedding properties for purposes of semantic search are often the result of combining various other properties. Embedding properties are sometimes just a string representation of (nearly) the entire record. Do this via transformations.
- Consider using LLMs to generate content for your embedding properties. For example, ask an LLM what questions a KB article answers and then embed those questions along with the article itself to better-match the search conditions. Do this via transformations.
- In the context of using an LLM to generate content (like responses to customers), it's often easier to solve problems by transforming datasets than by adding additional prompts to a flow. For example, if your KB articles say things like "Call support at 867-5309", your agent may make similar statements to your customers that you may not want. You can solve this through prompt chaining, but it is often more reliable and definitely lower-latency to transform the dataset (using an LLM) to remove such verbage altogether.
API Resources
API Resources enable agents to fetch or modify data in external systems. They encapsulate a URL and optional set of credentials behind a stable ID that can be referenced by any number of agents in a Call API behavior. This encapsulation makes it easy to uptake credential and URL changes as well as making it easier to port agents between stage and production environments where they might need to talk to different URLs.
For more information, please see the documentation for the Call API Behavior.
Updated 8 months ago