
Core Behaviors
The following Behaviors are common across all types of agents and represent the fundamental building blocks of any AI-enabled automation.
Execute Logic
The Execute Logic behavior allows you to author visual rules and actions against the context.
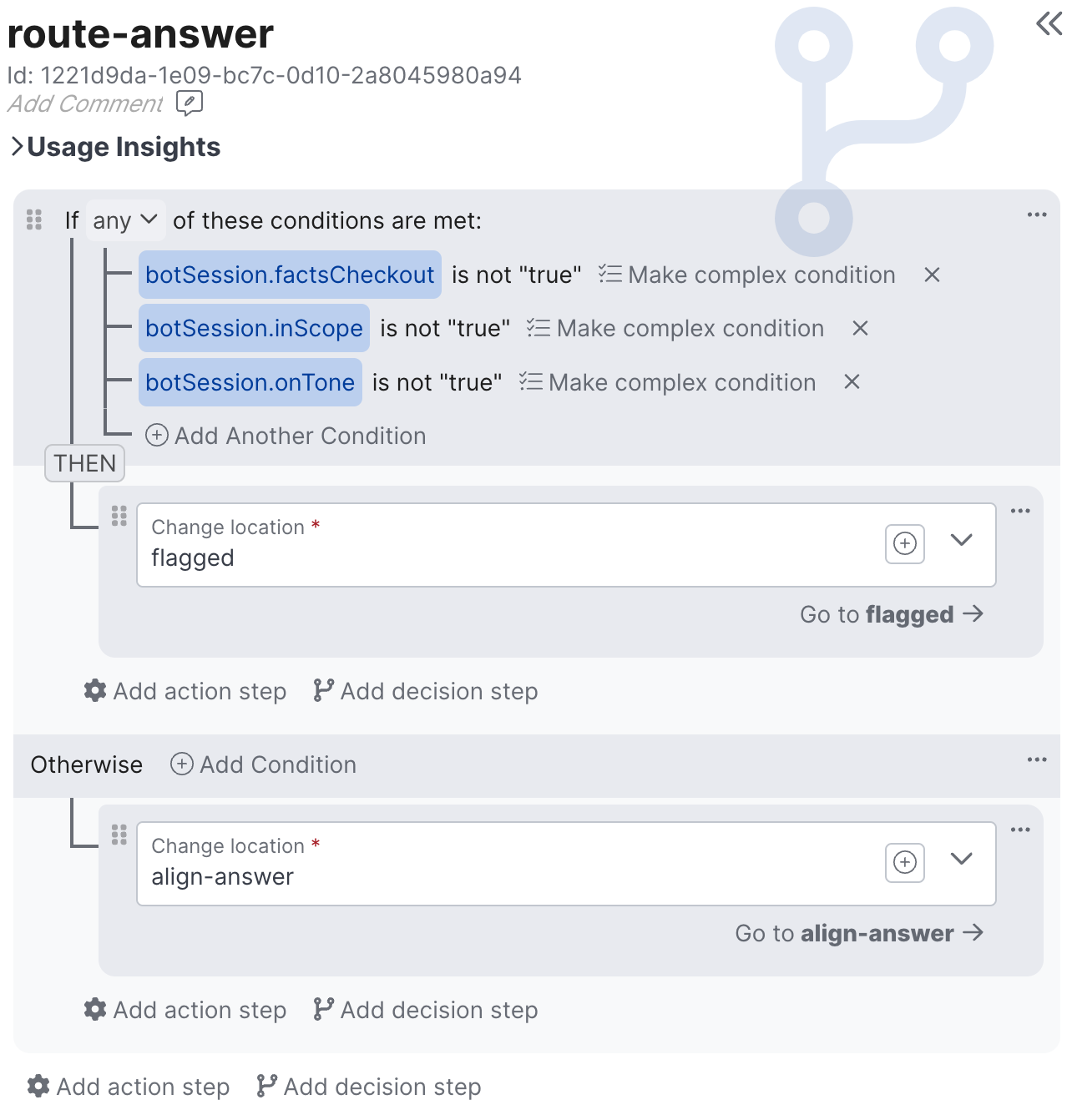
It's also possible to configure logic that executes when you enter or leave various other behavior types, so the choice to use an Execute Logic behavior can be largely stylistic. You may want to use an Execute Logic behavior if you want a piece of logic to be reusable and/or visible in the top-level Flow Graph to better explain the agent's behavior.
Search
The Search behavior allows you to search your AI Resources and attach the search results to the context. The search behavior is an integral part of achieving RAG .
You can configure multiple searches per behavior. For each search, you must specify the following:
- The resource to search
- The field on the context you wish to use as the search text
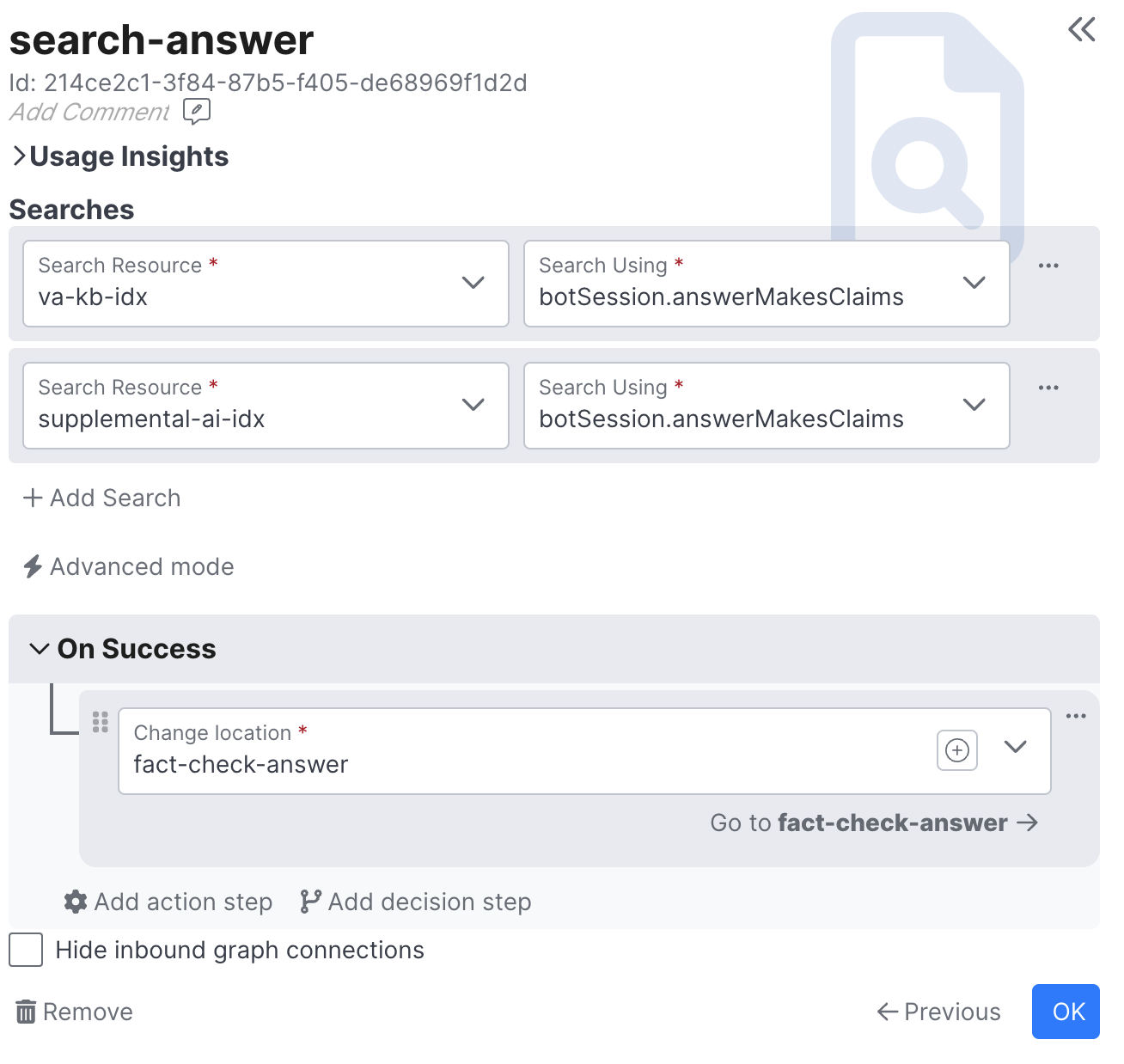
If you want to search directly on the customer's last message, use the handy customerLastMessage field on the context. It is common, however, to use an LLM to contextualize and/or rephrase the customer's last message prior to searching on it, in which case it must be stored in a session field as depicted in the screenshot.
Search Result Accumulation
Search results accumulate on the context and are available to Functions via the searchResults key.
Each element of searchResults represents a separate search invocation because there can be multiple search behaviors and searches per behavior. They accumulate in the order they executed. Within each invocation is a results array. Each element in the results array has the record from the dataset and its distance from the search text. Therefore, assuming we did a single search against a dataset whose records have a title property, we could extract & concat the title props as follows:
first_search = context['searchResults'][0]
titles = []
for result in first_search['results']:
titles.append(result['record']['title'])
print("\n".join(titles))There are helpers for finding & formatting search results in the Python Runtime's quiq.ctx module:
quiq.ctx.format_search_results('my-search-resource', "{title} - {body}")
For full documentation see the searchResults prop on the CustomerAssistantContext
Common usage patterns include:
- Incorporating search results in prompts to achieve RAG or aide in LLM decision making
- Using a Call Function node to directly derive rich message content from search results, such as constructing a carousel message based on a search against a product catalog
Search results are propagated as a flow chains through behaviors. However, they're cleared when flow execution stops (i.e. they're cleared after each user turn). If you wish to maintain search results across flow executions, consider using a buffer .
Web Search
The Web Search action allows information to be retrieved from the web, or a specific website, and used in generating a message or response. It's available across AI Agents, AI Services, and AI Assistants.
Web Search can only be added to a Search behavior while in Advanced mode. Once in Advanced mode, click Add, then select Web Search from the list of available actions:
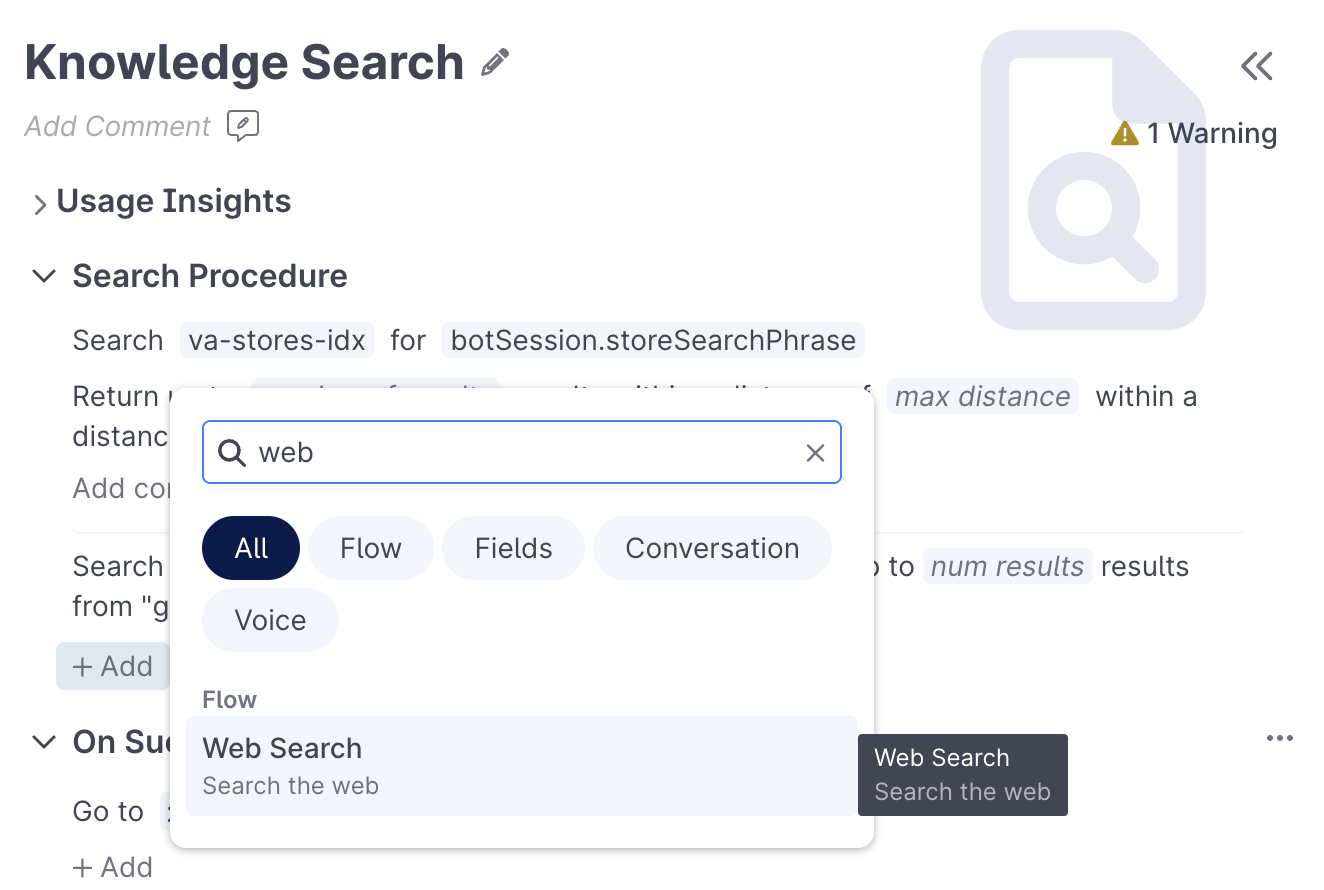
Configuring a Web Search action requires the following:
- Value: the search provider
- Search text: the search query. This is a required field. It supports a static input, or it can be dynamically populated from a bot, botSession, configs, conversation, environment, or prompts.completions field
- Return up to: the maximum number of results to return. Accepts a number from 1 to 10; entering a number outside that range clamps to the nearest bound
- Site: Constrains the search to a specific website.
Prompt AI
The Prompt AI behavior allows you to interact with any supported LLM to perform classifications or produce generative content.
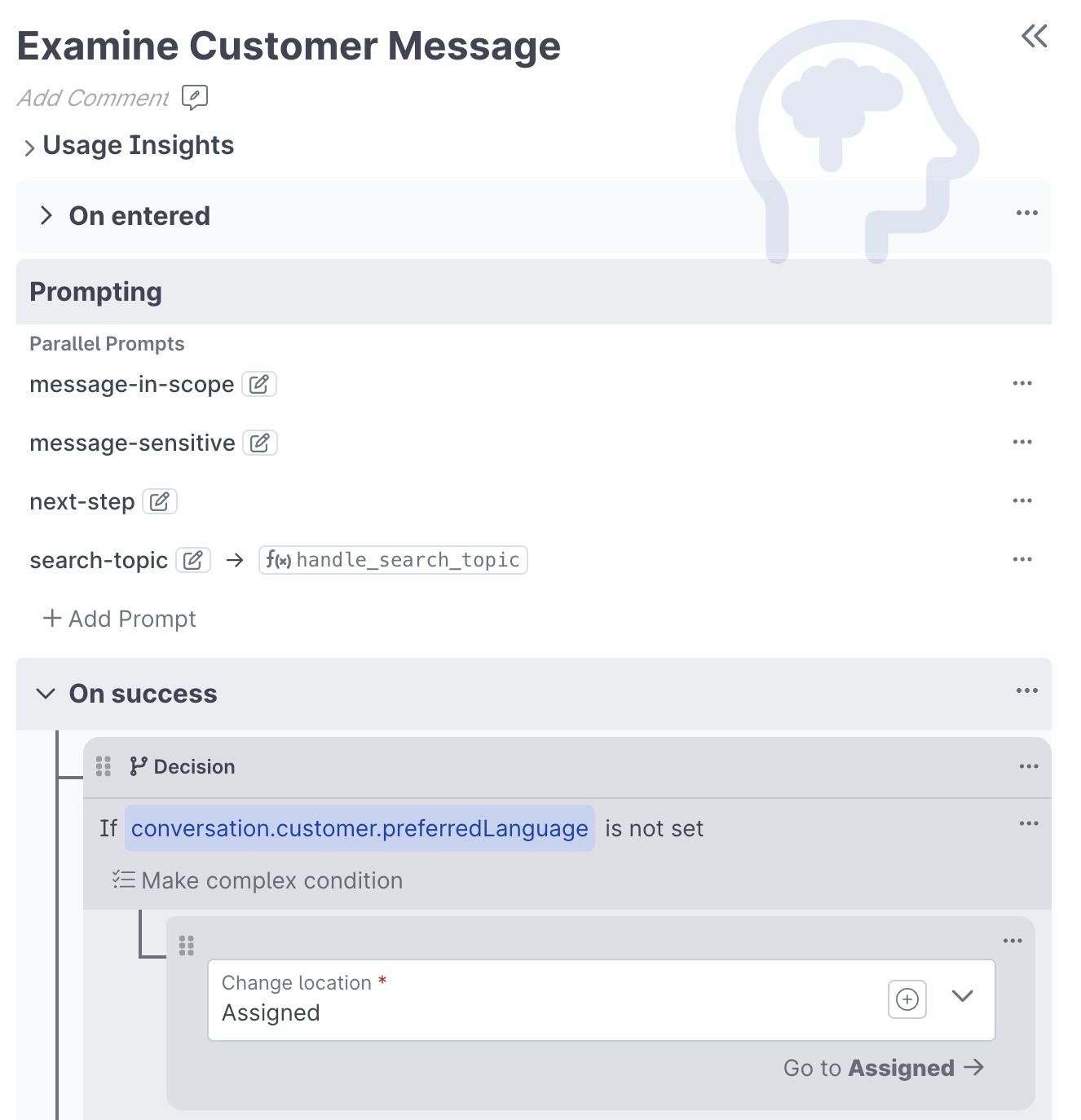
A single Prompt AI behavior can have multiple configured prompts that will execute in parallel. Parallel prompt execution is very helpful when trying to minimize an agent's response latency.
Each individual prompt configuration consists of the following:
- An identifier for the prompt
- An LLM selection such as
gpt-35-turbo-0613 - A reference to a Prompt Builder function. This function is responsible for translating the context into a prompt for the specified LLM.
- A reference to a Completion Handler function. This function is responsible for translating the LLM's prompt completion into actions
In addition to the prompt configurations, the Prompt AI behavior has three visual rule handlers:
| Rule Handler | Description |
|---|---|
| On Entered | Runs when then behavior is entered. If it executes a Change Location action then the rest of the Prompt AI Behavior will be short-circuited |
| On Success | Runs if all of the configured prompts execute successfully |
| On Error | Runs instead of On Success if any of the prompts experienced errors like Function syntax errors, token limit errors, etc. |
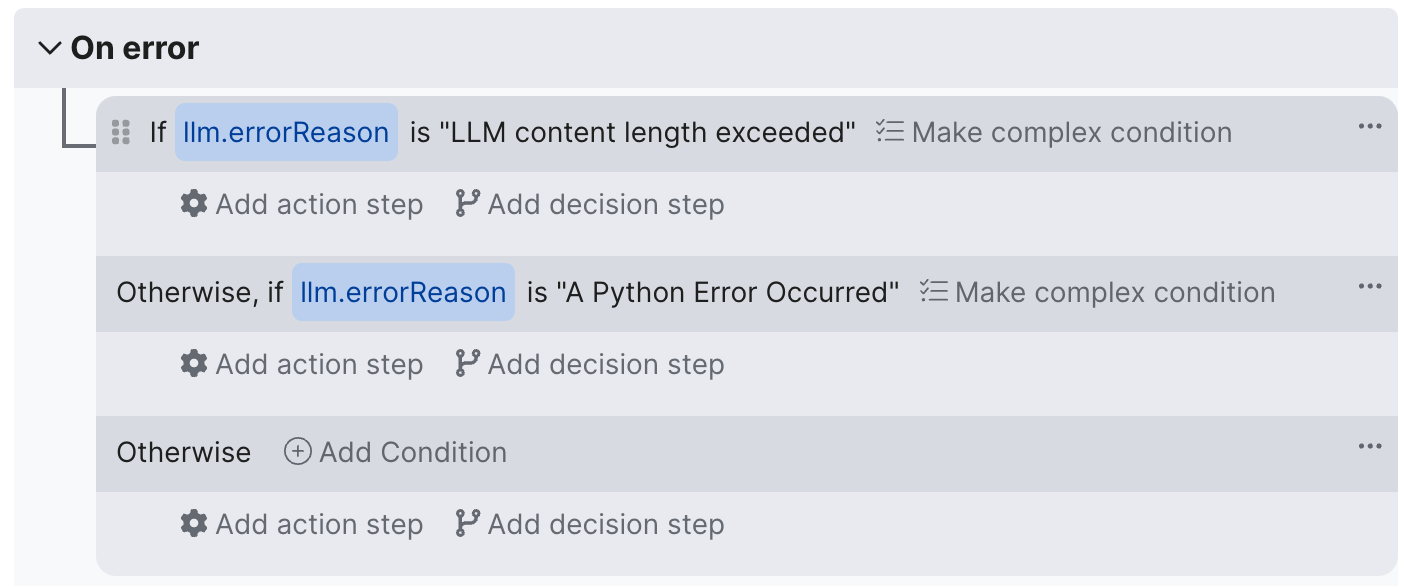
If the On Error handler is fired, it's possible to make decisions based on the type of error that occurred:
Prompt Variables
Prompt variables are a way to access prompt specific data during a user turn without having to manually set a session or conversation field. These fields are available when authoring actions and decision from the designer and will be nested under the prompts namespace followed by the prompt identifier. For example, prompts.identifier.completion.
Since these values only persist during a single user turn, it is recommended you assign them to a bot session or conversation field if they are needed for reporting or later in the flow.
| Fields | Description |
|---|---|
completion | The completion returned from the LLM unless overidden by the completion handler |
Prompt Builder Signature
Prompt builder functions are responsible for translating the context into a prompt. Prompt builder functions receive the following arguments:
| Argument | Description |
|---|---|
llm | The identifier of the selected LLM, such as gpt-35-turbo-0613 |
context | Contains all contextual data for prompt construction. The shape of context depends on the type of agent. Customer agents receive the CustomerAssistantContext. |
Prompt builder functions are expected to return a dictionary containing the following keys
| Key | Description |
|---|---|
request | The prompt request to be sent to the LLM. The shape of request will vary based on the target LLM |
The following Python example shows building a Customer agent prompt that simply takes the lastCustomerMessage from the CustomerAssistantContext and passes it directly to ChatCompletion-style OpenAI models:
def build_basic(llm, context):
content = context['derivedData']['lastCustomerMessage']
return {
"request": {
"messages": [{"role": "user", "content": content}]
}
}Completion Handler Signature
Completion handlers are responsible for translating the LLM completion into actions. Completion handler functions receive the following arguments:
| Argument | Description |
|---|---|
llm | The identifier of the selected LLM, such as gpt-35-turbo-0613 |
context | The same context object passed to the corresponding prompt builder |
prompt | The prompt request built by the corresponding prompt builder function |
response | The response payload received from the LLM |
completion | A short-cut to accessing the string portion of the LLM response |
Completion handler functions are expected to return a dictionary with any of the following keys:
| Key | Description |
|---|---|
actions | A list of programmatic actions to be executed - can be empty, null or missing |
completion | An optional way to override the completion prompt variable |
The following Customer agent completion handler example (Python) shows the completion text being sent directly back to the customer as a message:
def handle_basic(llm, context, prompt, completion):
return { "actions": [
{
"action": "sendMessage",
"message": {"text": completion}
}
]} Call API
The Call API behavior enables you to call off to external systems to either fetch and/or modify data. You can call any HTTP target configured in your API Resources.
The general pattern of a Call API behavior is context in and an optional sequence of actions out. You can build your API endpoint to accept a context in the request body and return a list of actions in the response natively, or you can enable the 'Use code' toggle to use a pair of Functions to adapt the context into your API's expected input format, and translate its response into a set of actions.
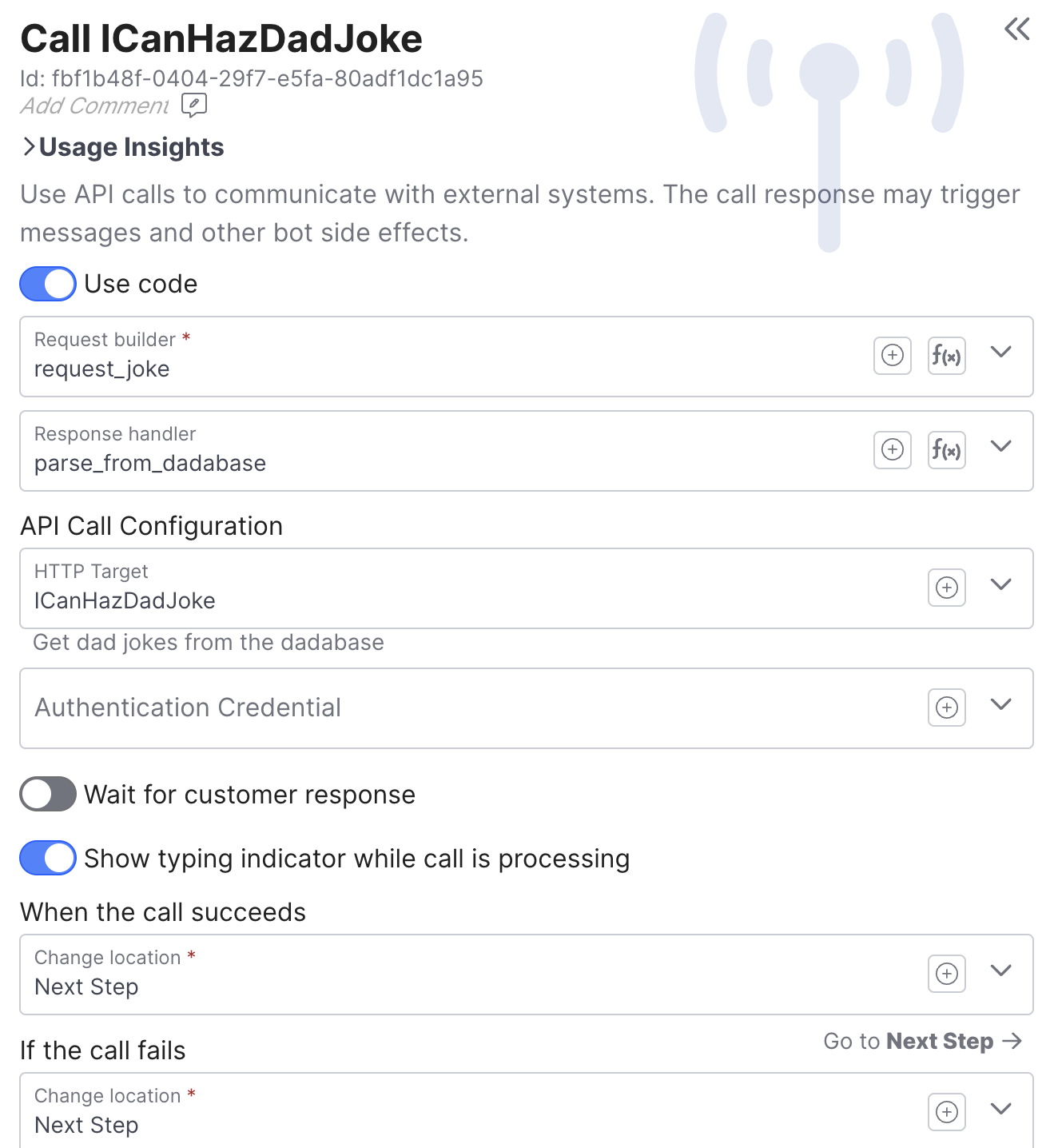
In this example we're calling the unsecured API at https://icanhazdadjoke.com/api to get a random joke. Since the endpoint wasn't designed specifically to be an agent API we're using two functions to translate the context into a request, and the response into actions:
def request_joke(context):
joke_topic = context['derivedData']['lastCustomerMessage']
return {
"headers": {"Accept": "application/json"},
"method": "GET",
"params": {"term": joke_topic},
"path": "/search"
}def parse_from_dadabase(response, context):
joke = response['body']['results'][0]['joke']
if joke:
return {
"actions": [
{"action": "sendMessage", 'message': {'text': joke}}
]
}When used in Customer agents, Call API behaviors have two additional configuration options:
- Wait for customer response - rest at this location until the customer responds (meaning the next flow execution for the current conversation will begin here)
- Show typing indicator - starts the typing indicator (same as the typing indicator action)
Because Call API behaviors call out to external system and use Functions they have the potential to fail. If any errors occur then the 'If the call fails' rule handler we execute, otherwise 'When the call succeeds' will execute.
Request Builder Signature
Request builder functions receive the following arguments:
| Argument | Description |
|---|---|
context | The current context. Customer agents receive the CustomerAssistantContext. |
and are expected to return a dictionary containing the following keys:
| Key | Description |
|---|---|
headers | An optional dictionary of header names to values. Not to be used for passing credentials but rather things like the HTTP Accept header |
method | The HTTP method to be used when calling the API e.g. POST |
params | An optional dictionary of query args (name: value) to be included on the request |
path | An optional path to be appended onto the HTTP target when making the call |
body | An optional request body |
Response Handler Signature
Request builder functions receive the following arguments:
| Argument | Description |
|---|---|
context | The current context. Customer agents receive the CustomerAssistantContext. |
response | The API response dictionary |
The response dictionary has the following keys:
| Key | Description |
|---|---|
statusCode | The response status code (int) |
headers | Response headers from the API as a dictionary |
body | The response body - if the response was JSON will be the result of json.loads(), otherwise it's the raw response text |
Response handlers are expected to return a dictionary with any of the following keys:
| Key | Description |
|---|---|
actions | A list of programmatic actions to be executed - can be empty, null or missing |
API Result Accumulation
Similar to search results, API Call results accumulate on the context in the apiResults key. This means you can defer creating actions from the API call response until later in the flow. Please note: result accumulation only occurs when Use Code is enabled.
Each element of the apiResults array corresponds to an individual Call API behavior invocation (they accumulate in the order they executed). Each element has the following props:
targetId: The ID of the HTTP Target (API Resource)request: The request built by the request builderresponse: The response from the API (same shape that is sent to the response handler function)
For full documentation see the apiResults prop on the CustomerAssistantContext
API results survive on the context for the duration of the user turn (current flow execution). If you want want them to persist longer consider using a buffer , or extract what you need via setField .
Call Function
Use Call Function anytime you want to use a Function to translate the context into actions independently of calling an LLM or an API.
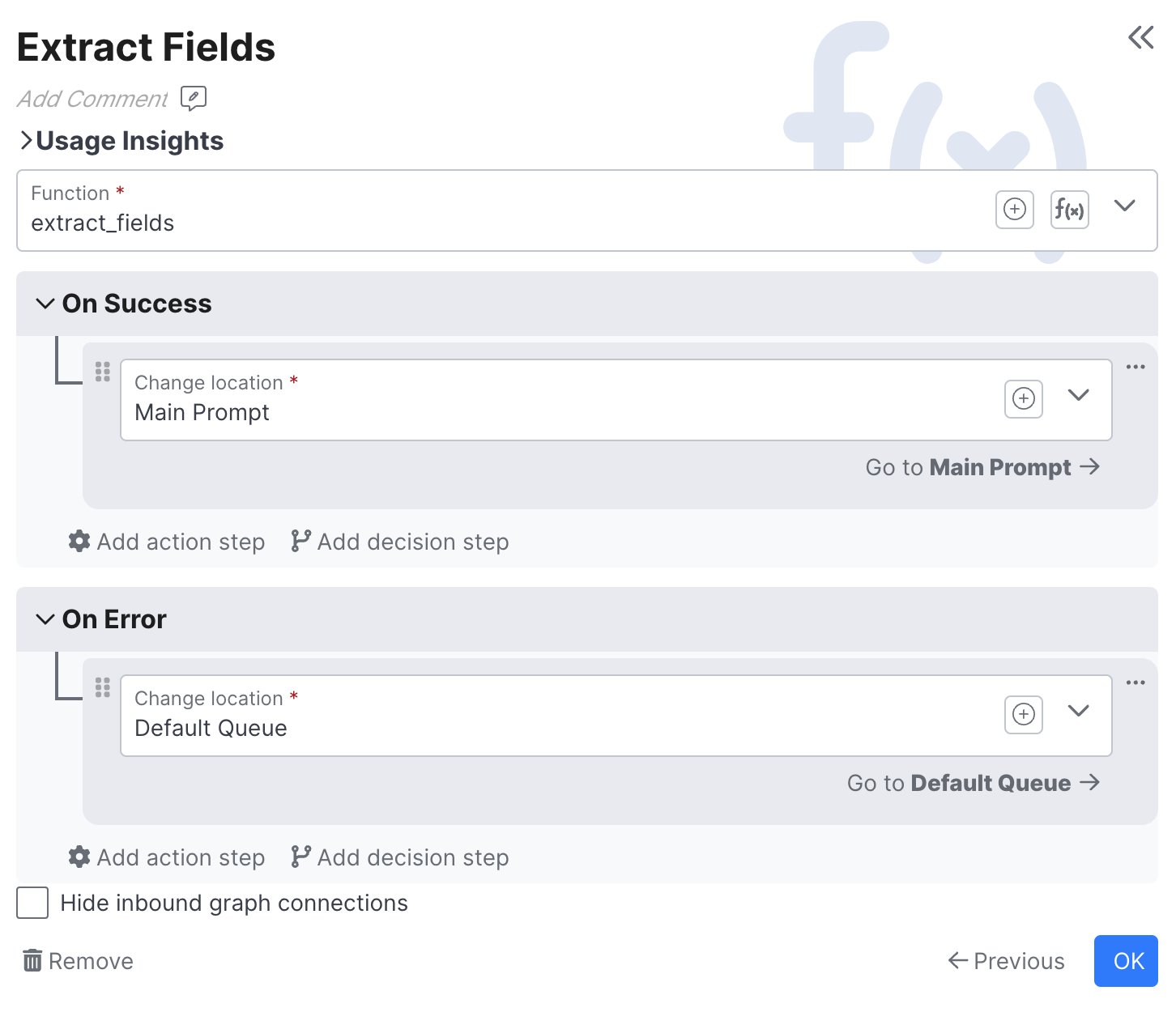
If the function executes without error, the On Success handler is called. Otherwise, the On Error handler is called.
Function Signature
Functions invoked by Call Function behaviors receive the following arguments:
| Argument | Description |
|---|---|
context | The current context. Customer agents receive the CustomerAssistantContext. |
and are expected to return a dictionary with any of the following keys:
| Key | Description |
|---|---|
actions | A list of programmatic actions to be executed - can be empty, null or missing |
Verify Claim
The Verify Claim Behavior allows you to determine if a claim made by an LLM is substantiated by the evidence such as search results. Like other Behaviors, you can get a detailed breakdown of how a particular claim was scored in the Debug Workbench.
Claim
Select the Claim to be verified, the Claim can be from a botSession field, or from a Prompt completion:

Verification Model
In addition to selecting the Claim you'd like to verify, you'll need to select a model to evaluate the claim. Quiq currently supports the Vectara hallucination evaluation model, which is a purpose built AI model designed to detect hallucinations.
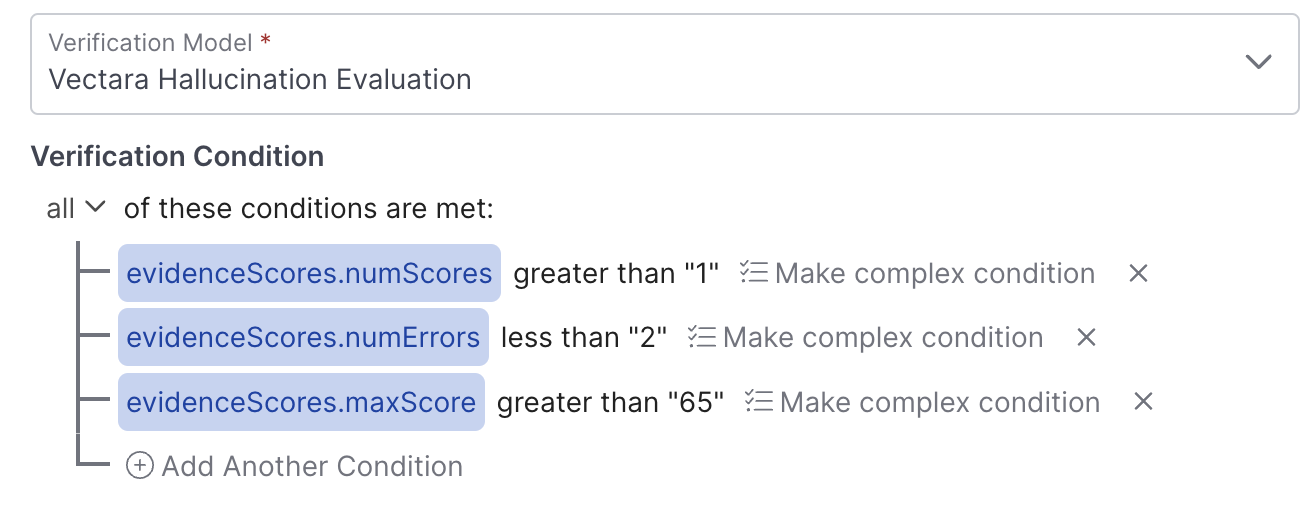
Verification Condition
When verifying a Claim, you'll want to define the rules that determine when a Claim is verified, below are some of the fields that can be leveraged:
| Field | Definition |
|---|---|
| evidenceScores.maxScore | The maximum evidence score |
| evidenceScores.meanScore | The average evidence score |
| evidenceScores.minScore | The minimum evidence score |
| evidenceScores.numErrors | The number of pieces of evidence that had errors |
| evidenceScores.numScores | The number of scored pieces of evidence |
Scores work on a 0 - 100 scale, with a lower score indicating that the Claim is less substantiated by the evidence provided.
These conditions can be combined with one another to create the verification conditions that make sense for your use case:
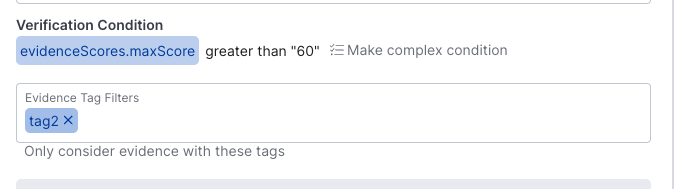
Evidence Tags
In the Function Editor, tags can be added to your parse_evidence function, that can then be used to filter evidence that contains certain tags.
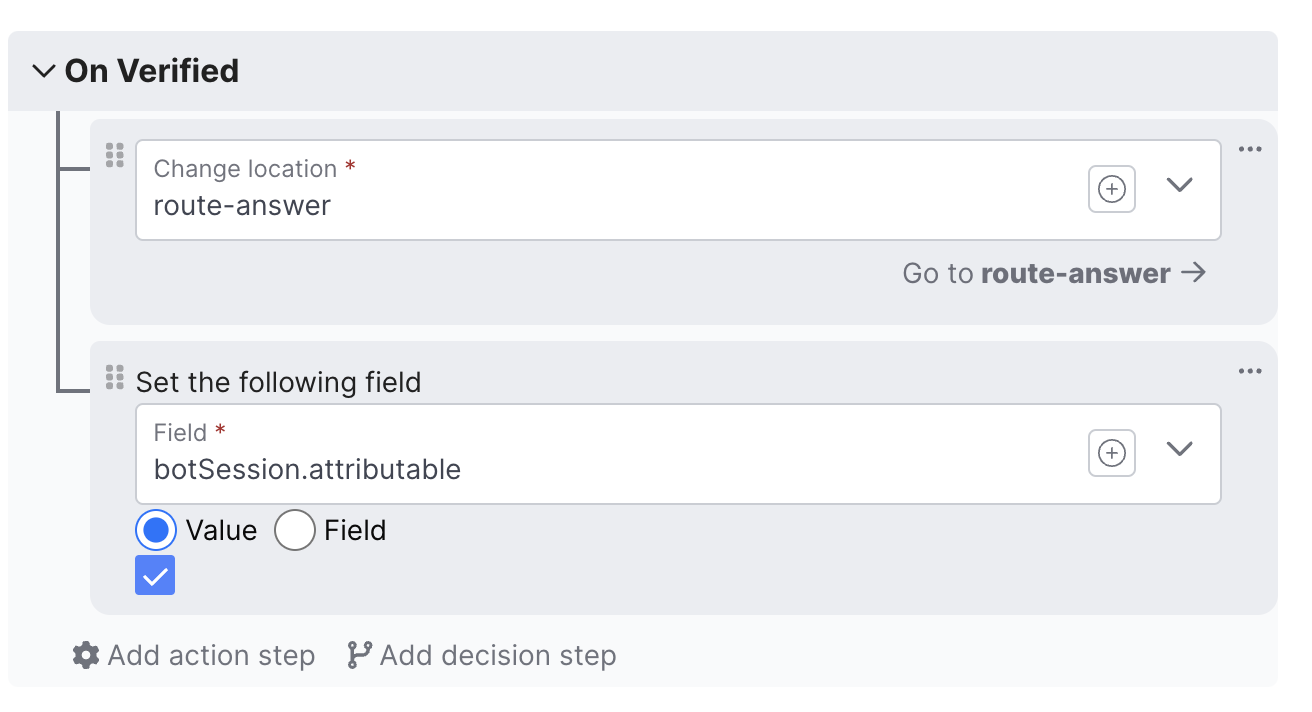
On Verified
Define actions and decision steps when a Claim is verified.
On Unverified
Define actions or decision steps when a Claim is unverified.
Document
The Document behavior allows your AI Agent, Assistant, or Service to reference a Process Guide or other content throughout the experience. Documents are written using natural language and can be referenced in the Function Editor.
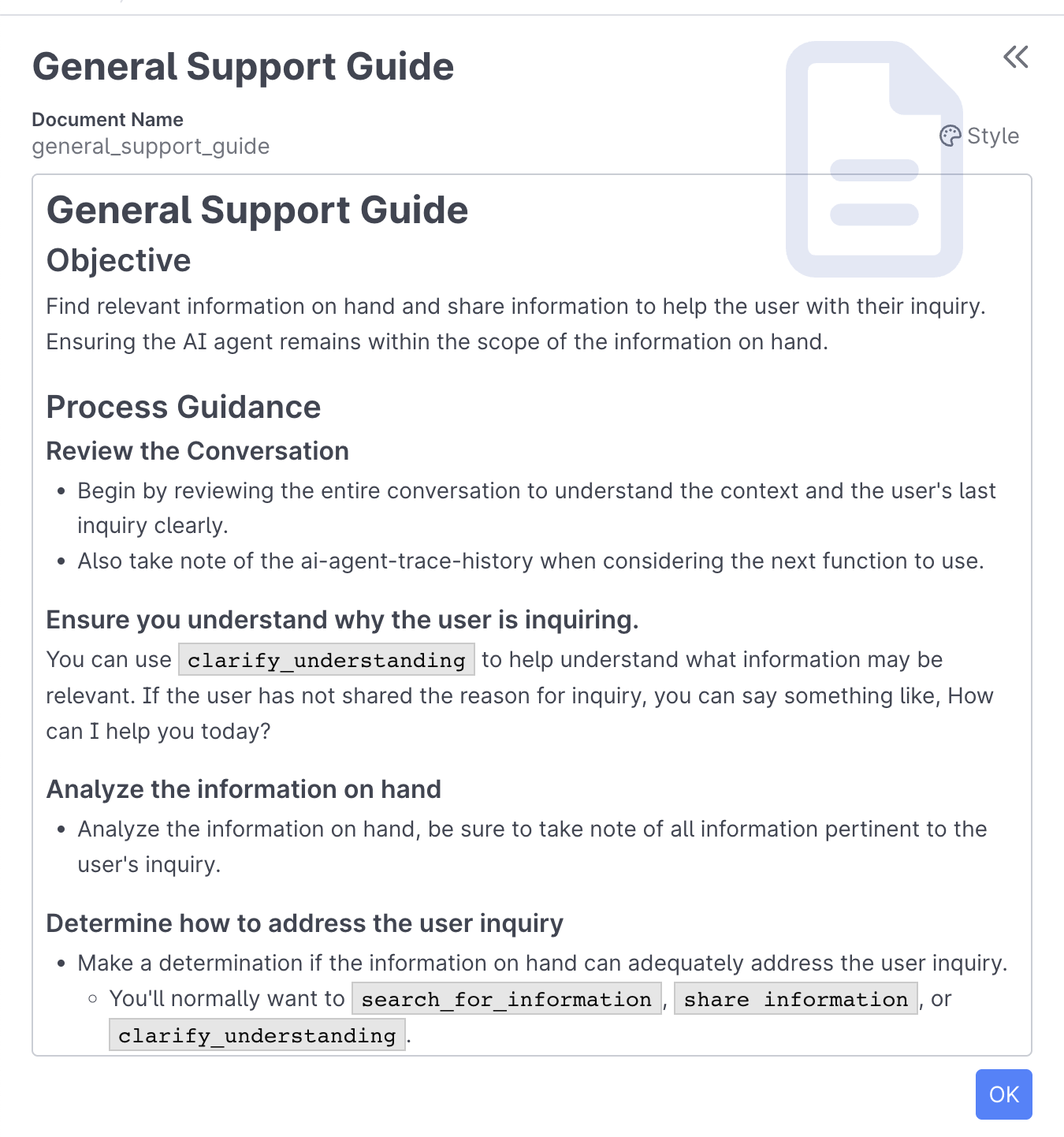
Documents provide a way to give your AI agent detailed instructions, context, and processes without hardcoding them into your functions. This makes your agent behavior easier to maintain and update since you can modify the document content without changing code.
Using your Document
Your Document can be referenced in the Function Editor using the Document name, eg general_support_guide in the example shared above.
Updated 7 days ago